sikulixのOCRで日本語を読み取る設定手順とサンプルコード解説
sikulixにはディスプレイに表示された文字を読み取るOCR機能がありますが、デフォルトの設定は英語のみで、日本語の読み取りには対応していません。
そこで、sikulixの日本語を読み取るOCRの設定方法と、実際に読み取るサンプルコードの書き方を解説したいと思います。
sikulixのOCRで文字を読み取り
RPAツールとしても利用できるsikulixには、文字読み取りできるOCR機能が備わっています。
例えば、以下のような構文で対象画像からOCRで文字を読み取り、OCRの実行結果をstrという変数に保存することができます。
str = find("OCR対象の画像").text()
text()メソッドを使うことで、たった1行でOCRを実行できるほど、sikulixでは簡単にOCRを実行できます。
OCRの読み取り結果を保存した変数を処理することで、RPAとして業務改善に活用が可能です。
sikulixのOCRはデフォルト英語に対応
sikulixのOCR機能は、デフォルトのインストール状態では英語にのみ対応しています。
メモ帳に書かれた文字を探して、テキストに変換し、結果をメッセージに表示するサンプルコードです。
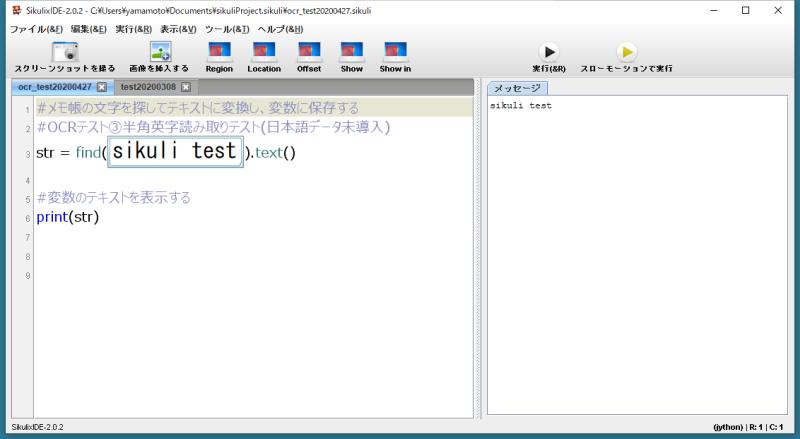
スペルミスもなく、きちんと英語のアルファベットが正確にOCRで読み取ることができています。
さらに、数字の場合も同様にOCRが可能です。
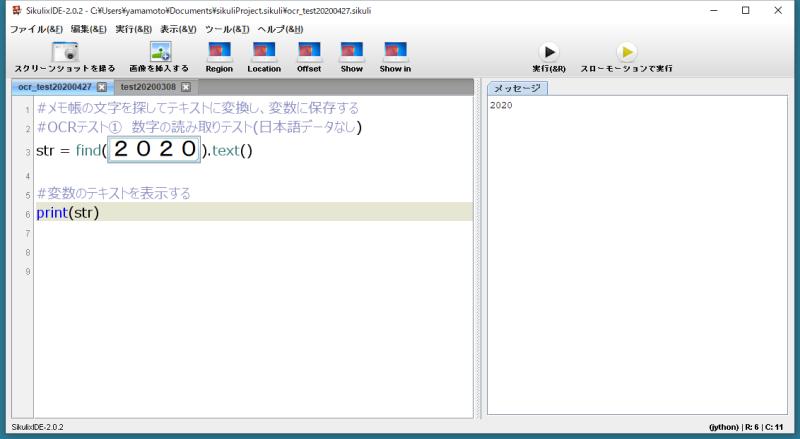
このような数字や半角文字のアルファベットであれば、問題なく読み取ることができます。
ひらがなや漢字は読み取りに失敗
しかし、sikulixは全角文字である日本語のOCRにはそのままでは対応していません。
そのため、ひらがなや漢字を読み取ろうとすると、上手く読み取ることができず、OCRとしての機能を果たすことはできません。
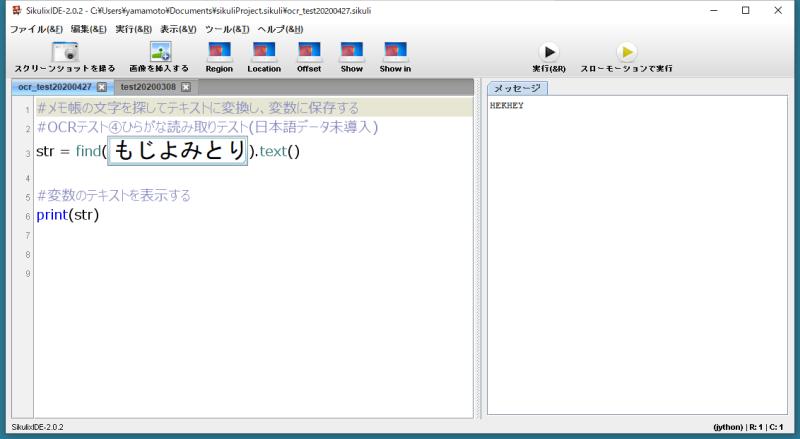
英語や数字と同じサンプルコードで読み取り対象を「もじよみとり」というひらがなで検証したところ、まったく読み取ることができていません。
RPA業務でOCRを行う場合には、2020年●月や氏名、項目などの日本語の読み取りは必須です。
そのため、日本語が読み取れない現状では、RPA業務にsikulixを取り入れるのは難しいです。
ただ、sikulixで日本語のOCRも対応するように設定を行えば、日本語も認識できるようになります。
sikulixのOCRを日本語に対応する方法
sikulixのOCRでひらがなやカタカナ、漢字などの日本語に対応するための設定方法について解説します。
sikulixをインストールした状態では、OCRに日本語用のデータが含まれておらず、英語用のデータのみ存在する状態です。
そこで、日本語用のOCRデータを準備することでsikulixで日本語の全角かなや漢字の読み取りができるようになります。
sikulixではOCR用エンジンとして「Tesseract(テッセラクト)」を利用しています。
Tesseractには英語以外に様々な言語用の学習データが用意されており、その中から日本語用のデータをsikulixに設定することで、日本語のOCRが可能になります。
sikulixにTesseractの日本語用OCRデータ導入手順
1.Tesseractの日本語学習データがあるgithubページにアクセスします。
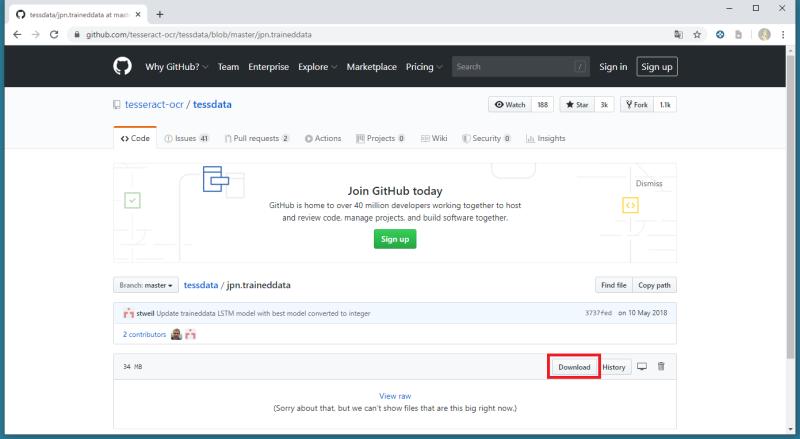
2.githubに置かれている「jpn.traineddata」を「Download」ボタンをクリックして、ダウンロードします。
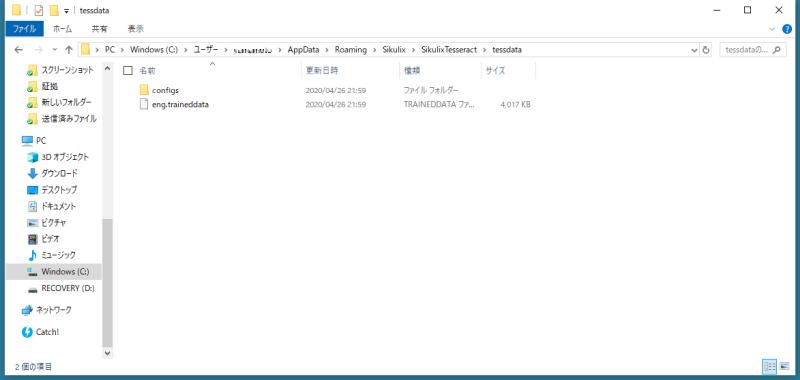
3.sikulixをインストールした際にTesseract格納されているフォルダに移動します。
WindowsOSの場合、デフォルトのインストールでは、以下のディレクトリに該当します。
C:\Users\(ユーザー名)\AppData\Roaming\Sikulix\SikulixTesseract\tessdata
※ユーザー名の部分はWindowsOSのユーザー名が入ります。
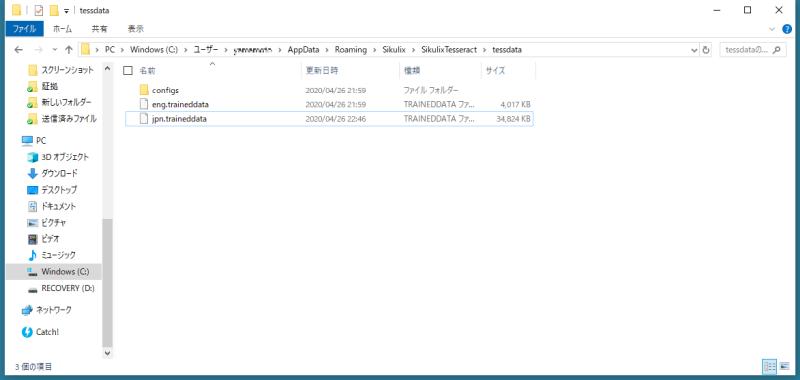
4.githubからダウンロードした「jpn.traineddata」を前述のディレクトリに格納します。
以上の4StepでsikulixのOCR日本語対応の設定は完了です。
sikulixを起動していた場合は再起動すると、OCRで日本語を読み取りが可能になります。
日本語を読み取るsikulixのOCRサンプルコード
sikulixにTesseractの日本語データの設定を行ったので、実際に日本語を読み取るサンプルコードを用意してみました。
# デフォルト文字コードをutf-8に変更する
import sys
reload(sys)
sys.setdefaultencoding("utf_8")
#OCRの読み取り言語を日本語に変更する
tr = TextOCR.start()
tr.setLanguage("jpn")
#メモ帳の文字を探してテキストに変換し、変数に保存する
#OCRテスト⑥漢字読み取りテスト(日本語データ導入済み)
str = find("OCR対象のキャプチャ画像").text()
#変数のテキストを表示する
print(str)
まず、1-4行でsysライブラリを読み込み、sys.setdefaultencoding(“utf_8")で文字コードをutf-8に設定します。
通常は日本語に対応しない文字コードが設定されており、表示ができないためです。
続いて5-7行でOCRの読み取り言語の変更です。
setLanguageメソッドで通常は英語「"en"」が指定されているものを「"jpn"」に変更します。
最後にOCRしたい対象を選択した画像をOCRで読み取り、その結果をメッセージに表示させます。
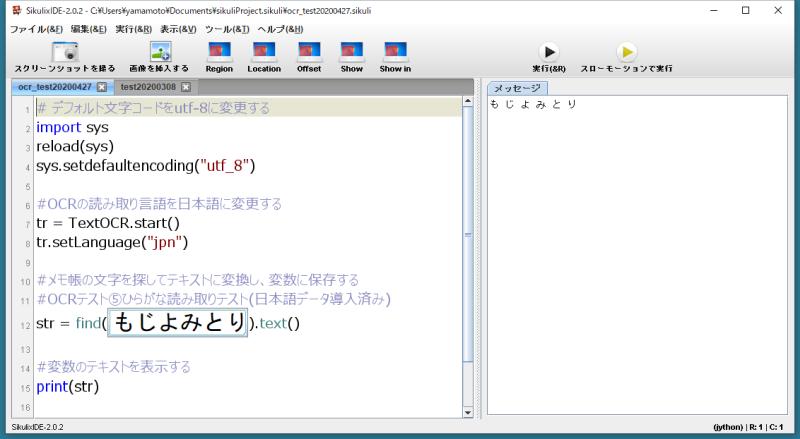
実際にサンプルコードを走らせると、右のメッセージタブに結果が表示されます。
前述では日本語のひらがなを読み取ると、上手く結果が出力されませんでしたが、きちんと「もじよみとり」が出力されています。
読み取り後の文字列操作は不可欠
なお、日本語読み取り設定を有効にし、sikulixのOCRで日本語を認識できるようになっても注意が必要です。
注意点として、読み取った際には文字と文字の間にスペースが挿入されることが挙げられます。
そのままでは読み取った文字にスペースが含まれているので、単語として認識できません。
読み取った後の文字列で、trimなどのスペースを除去する文字列操作や処理が必要です。
また、OCRは常に誤認識と隣合わせで、特に手書きの文字の認識率は低くなります。
上手く認識できなかった場合の処理も含め、sikulixのOCR認識処理を行うコードを記述する必要があります。
まとめ・終わりに
今回、sikulixのOCR機能で日本語にも対応させる設定方法と、実際に日本語OCRを行うサンプルコードを解説しました。
sikulixのデフォルトインストールでは、英語用のOCRデータしかないため、日本語に対応に対応していません。
しかし、日本語データをダウンロードし配置することで日本語も読み取り可能になります。
RPAの業務自動化ではOCRを使った業務改善に取り組む事例が多いです。
その中で日本語を読み取る作業は必須になるので、ぜひ、今回の設定方法とサンプルコードを参考にしてみてください。