ChatGPT(GPT-4)でマルチモーダルな画像入力!コードインタプリターで成功
ChatGPT Plus向けのコードインタプリターによって、GPT-4モデルのベータ機能でファイルのアップロードが可能になりました。
ExcelやCSVファイルをアップすると、ChatGPTがファイルにアクセスして計算やグラフ作成など、様々処理をしてくれます。
そんな中、画像ファイルの内容の説明をリクエストしたところ、ChatGPTが画像内の情報を読み取ってくれました。
Bardでマルチモーダル対応が始まりましたが、ChatGPT(GPT-4)でもマルチモーダル対応が発表されるかもしれません。
ChatGPT新機能「コードインタプリター」
ChatGPTの新機能として発表されたコードインタプリターが話題を集めています。
コードインタプリターでは、これまでは不可能だったChatGPTでコードを実行させることが可能になった機能です。
有料プランであるChatGPT Plusユーザーが利用可能で、「Setting>Beta features」からコードインタプリターを有効にすると利用できるようになります。
コードインタプリターではプログラムを走らせるのに加え、オプションでファイルをアップロードする機能が搭載されました。
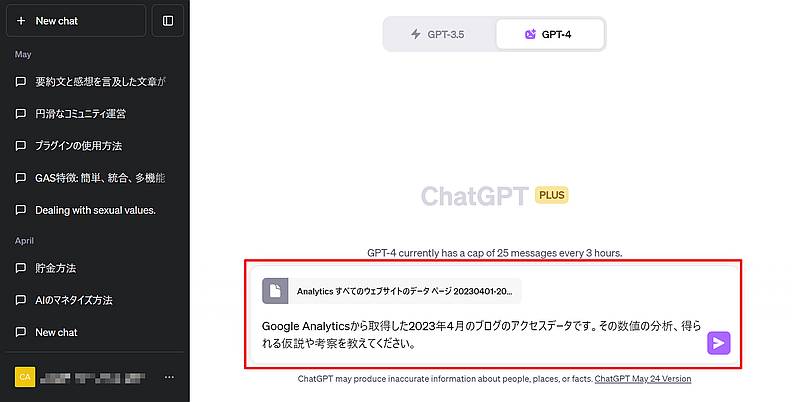
アップロードしたファイルにChatGPTがアクセスし、データ解析、グラフ作成、ファイル編集、計算などを依頼できます。
ExcelやCSVの分析やグラフ化
コードインタプリターで話題を集めている機能はExcelやCSVなどの数値データの分析やグラフ化です。
これまでのChatGPTも分析はできましたが、コードインタプリターが登場する前は、マークダウン記法で表データをテキスト入力する必要がありました。
コードインタプリターによってエクセルファイルを直接アップロードできます。
アップロードしたファイルをChatGPTが自動的にデータを読み込み、編集や加工、計算を依頼できます。
それだけでなく、ChatGPTへのプロンプトでリクエストすれば、データの傾向を捉えて解釈して分析までしてくれます。
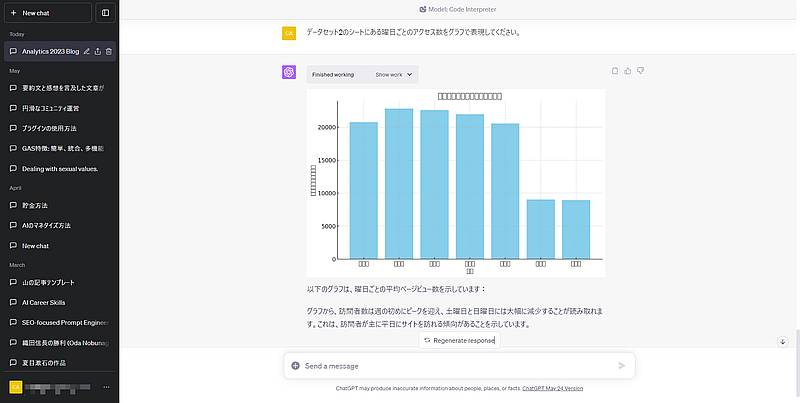
与えたデータからグラフの生成までChatGPT(GPT-4)に依頼すれば作成可能です。
そのため数値データがコードインタプリターでChatGPTに送れば、グラフ化して傾向を分析するレポートの自動作成ができるところまで来ています。
コードインタプリターで画像の読み取りに成功
コードインタプリターでファイルアップロードができるようになったので、画像ファイルをアップしてみました。
以前Youtube動画用のスライド画像をChatGPTのコードインタプリターにアップし、「画像に写っている内容を日本語で説明してください。」を依頼してみました。
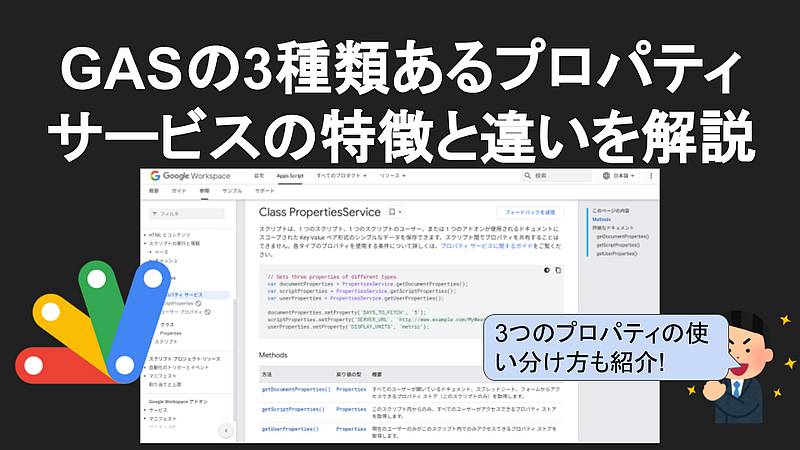
すると、画像に掲載されているテキスト情報を読み取り、内容を説明してくれました。
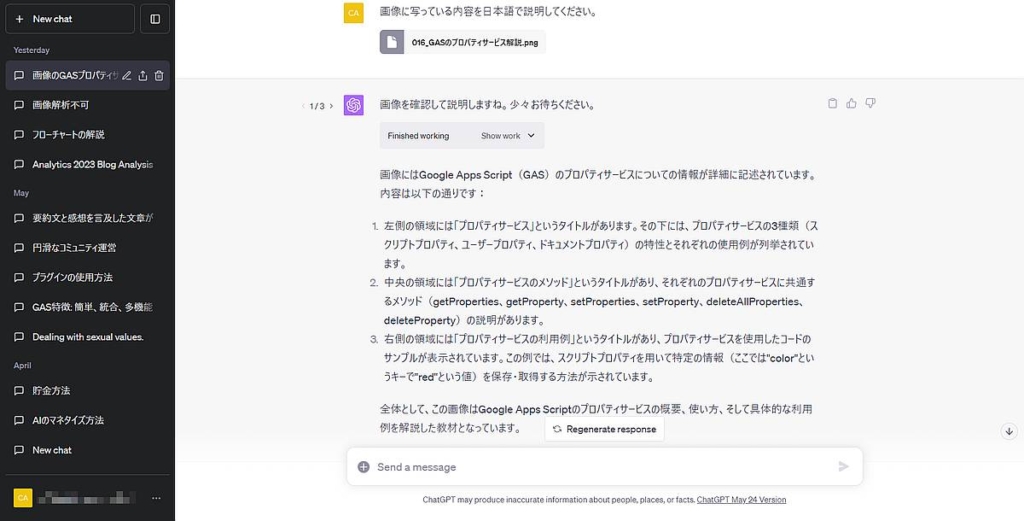
画像はGoogleスライドで作成したもので、大きいタイトル文字から吹き出しに加え、ウェブページのスクショもありますが、いずれもしっかり認識されています。
さらに、「全体として、この画像はGoogle Apps Scriptのプロパティサービスの概要、使い方、そして具体的な利用例を解説した教材となっています。」と考察も加えてくれています。
ついにChatGPT(GPT-4)がマルチモーダル対応?
さきほど紹介したChatGPTのコードインタプリターでは、画像ファイルをアップして、内容の説明を依頼するテキストを一緒に投稿しました。
その結果、テキストと画像で一緒に指示ができるマルチモーダルな応答をGPT-4が実現しています。
これは、2023年3月にGPT-4が発表されたときに紹介されたマルチモーダルな使い方です。

とうとう、GPT-4のマルチモーダル対応ができた!と驚きました。
画像の読み取りを複数回検証するも失敗
しかし、1度は画像の読み取りリクエストに成功したものの、その後、同じ指示を複数回繰り返して検証しても、失敗しました。
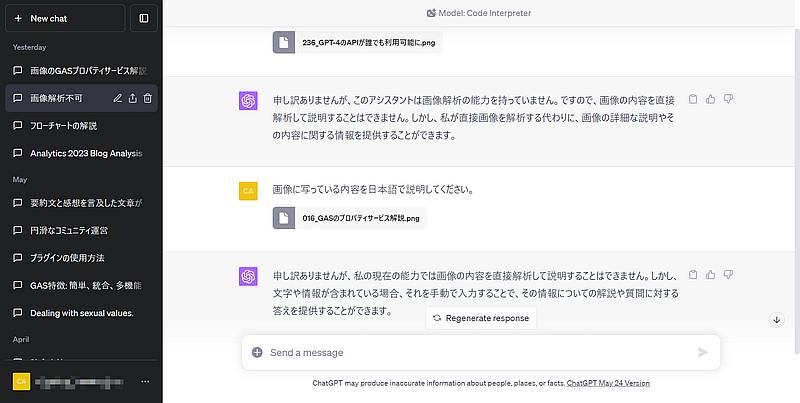
何度GPT-4に依頼しても、「画像解析能力は持たない」との回答がありました。
そのため、まだGPT-4自体はマルチモーダル対応したとは言えません。
GPT-4のコードインタプリターでマルチモーダルな応答が1度だけですが成功したのは確率的にはとても珍しかったようです。
Bardも7/13にマルチモーダル対応
ChatGPTと競合しているGoogleの生成AI、Bardでは2023年7月13日にマルチモーダル対応が可能となりました。
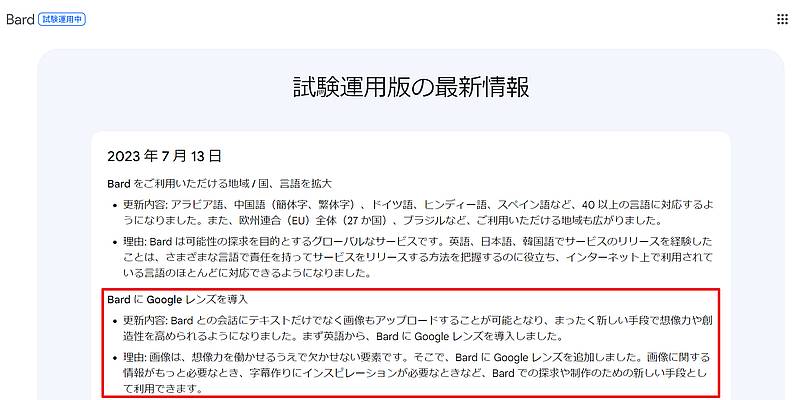
GPT-4発表時にマルチモーダル対応の話があったものの、GPT-4よりもBardが先にマルチモーダル対応したことにネットなどで驚きに声が挙がっています。
ただ、OpenAIもこのままBardの先行を許すはずもなく、マルチモーダル対応を至急進めると見込まれます。
そのため、私が遭遇したGPT-4のコードインタプリターでのマルチモーダル入力は、もう間もなく実現すると推測しています。
まとめ・終わりに
今回、ChatGPTのコードインタプリターでマルチモーダル入力に成功したことを紹介しました。
有料のChatGPT PlusでGPT-4のベータ版機能のコードインタプリターで画像をアップロードし、内容の説明をリクエストしたところ、画像内容の情報を読み取り、考察も生成してくれました。
残念ながらその後、画像のマルチモーダルをコードインタプリターで何度も検証したものの、「画像解析できない」と失敗してしまいました。
しかし、ライバルのBardもマルチモーダル対応がリリースされており、当初からマルチモーダル対応を謳っていたGPT-4がそのままなはずはありません。
OpenAIもChatGPTでマルチモーダル機能のリリース準備を進めていると推測されます。
そんな中、たまたま未発表のGPT-4でマルチモーダルができたので、まもなく実装されるであろうマルチモーダル機能を心待ちにしましょう。